语音合成
目录
流萤的语音合成,请勿用于非法用途
本文将分享流萤的语音合成模型的训练、部署和使用方法。模型基于 GPT-SoVITS,并在此基础上进行微调。提供了本地和服务器部署的教程。
0. 效果预览 #
0.1 模型_v4_20250729 #
模型部署在 Colab 上可以用来听书。感谢 tux_la 的视频演示!
0.2 模型_v2Pro_20251118 #
希望,是一只带有羽毛的东西
它在我的灵魂中筑巢栖息
唱着没有词的俚曲
似乎永远不会停息。在风中能听到它唱的最为甜蜜
只有强劲的风暴会阻止它的足迹
迫使这只小鸟暂时静寂
而它曾经给过多少人带去了暖意。我在最寒冷的土地上,听到过它的鸣啼
我在最奇特的海面上,也听到过它的歌曲
然而,从来没有,在极端的境地
它向我索取过一点点的东西。——艾米莉·狄金森 《希望是一只带有羽毛的东西》
关于 Colab 的部署,请参考 第三部分。
0.3 模型_v2ProPlus_20260403_DPO #
所以,再答应我一个愿望……
还记得吗?在对抗「太一之梦」的时候,我抱着你飞上天空。那时,我不知道自己还能否醒来,但我却很开心。
因为,我们又能肩并肩,去对抗某些我们认为「不对」的东西,并且,能为对方不顾一切。
不过,我还是有一点小小的私心——我相信你不会忘记这一幕,但如果回想起来,我想让它轻松一点。
也许没有什么敌人,一切只是场恶作剧。而我抱着你飞上天空时,天空中不是可怕的虫群,而是…我没能看到的烟花。
…艾利欧说,我们注定走向不同的终末,不可能拥有未来。
所以你说,你会给我一个,比任何结局都美好的白日梦。
我很期待…但是,我们难道真的就不能,一起跨过那个结局吗?
我不害怕死…但不要让我独自一人死去……——终末任务《记忆是梦的开场白》
- 这个不建议四句一切(容易丢失内容)。由于是长句训练的,选择句号切分效果相对较好。
- 参数完全保持默认即可。当然可以尝试调整别的参数,不过我还没有找到明显更好的值。
一些啰嗦:
- 上面三个模型均只使用了 3.8 以前的剧情语音。
- 使用包含了 3.8 以后的语音的模型正在
咕咕训练中。
- 使用包含了 3.8 以后的语音的模型正在
- GPT-SoVITS 没有提供 GPT 模块返回空 token 后重试的功能,因此会不可避免地丢失内容(一般是一整个分句),特别是长文本。我在设法解决这个问题。
- 即使是最新的 v2ProPlus 模型,也很难完全避免在某些节点丢失频段,听起来像是“咔咔”的声音。
0.4 关于 Genie-TTS #
Genie-TTS 是一个基于 GPT-SoVITS 的语音合成工具,专注于推理。内置了从原始 pth/ckpt 模型到 onnx 模型的转换工具,在此过程中,通过将原始模型量化以减小占用,实现了在 CPU 上的高效推理。
注意事项:
- 运行 Genie-TTS 大约需要使用 4~6GB 内存。如果推理时出现程序闪退、桌面图标消失等问题,就大概率是内存不足导致的。
- 可以尝试关闭其他占用内存较大的程序,启用内存扩展,或者禁用 RoBERTa 组件。
- 禁用 RoBERTa 组件可以使占用内存降低至 4GB 左右,但会导致语气、停顿等效果大幅下降。
- 由于模型已经从 fp32 量化为 fp16(而不是 bf16),减少了解空间的范围,所以相比起原始模型,其语音质量会有(可能非常明显的)下降——尽管运行时重新拉回了 fp32。特别是气息、停顿部分会有较大的影响。对于流萤的模型来说,三个模型的受影响程度都比较大,不太推荐使用。
- 由于导出的
onnx写死了贪婪搜索,所以无法调整温度、top_p,无法通过调整这些参数来改善质量。 - 部分报告表明 Genie-TTS 在多音字、跨语种等方面的表现不佳,可能会出现发音错误、语调不自然等问题。
关于 Genie-TTS 的使用,请参阅 官方文档。
原版 Genie-TTS 支持 Windows
本人制作了 Genie-TTS 在 Android 上的整合包,需要使用 Termux 作为运行环境,使用方法参阅 第五节。
1. OOTB(开箱即用)的食用方法 #
部分参考原著 GPT-SoVITS 指南
主要是推理(也就是合成语音),微调请看后面。
1.1 下载文件 #
-
前往 RVC-Boss/GPT-SoVITS 下载整合包,并在 合适的 位置解压
- 理论上哪都可以,但是不建议放在带空格(分割问题)/中文路径(编码问题)下
-
去 仓库 的
lovefirefly-archive/语音合成/模型下载模型以及参考语音.7z现在模型有三个,分别是
模型_v4_20250729.7z、模型_v2pro_20251118.7z和模型_v2proplus_20260403.7z,这里展示的是v4的版本。
v2pro和v2proplus操作完全相同v4是最早的版本,在本地的 NVIDIA GeForce RTX 5070 Laptop GPU 上微调。由于显存较小(8GB),所以切分较碎,句间停顿能力稍弱。v2pro在服务器上使用未切分的数据微调,长句能力大幅提升。但是温度、top_p 太高会有极其轻微的咔咔声。请务必按照推荐参数调整。v2proplus在服务器上使用未切分的数据微调,长句能力进一步提升。减少了默认参数下的咔咔声。
完成后大概是下面的样子(选中的就是下载的文件)
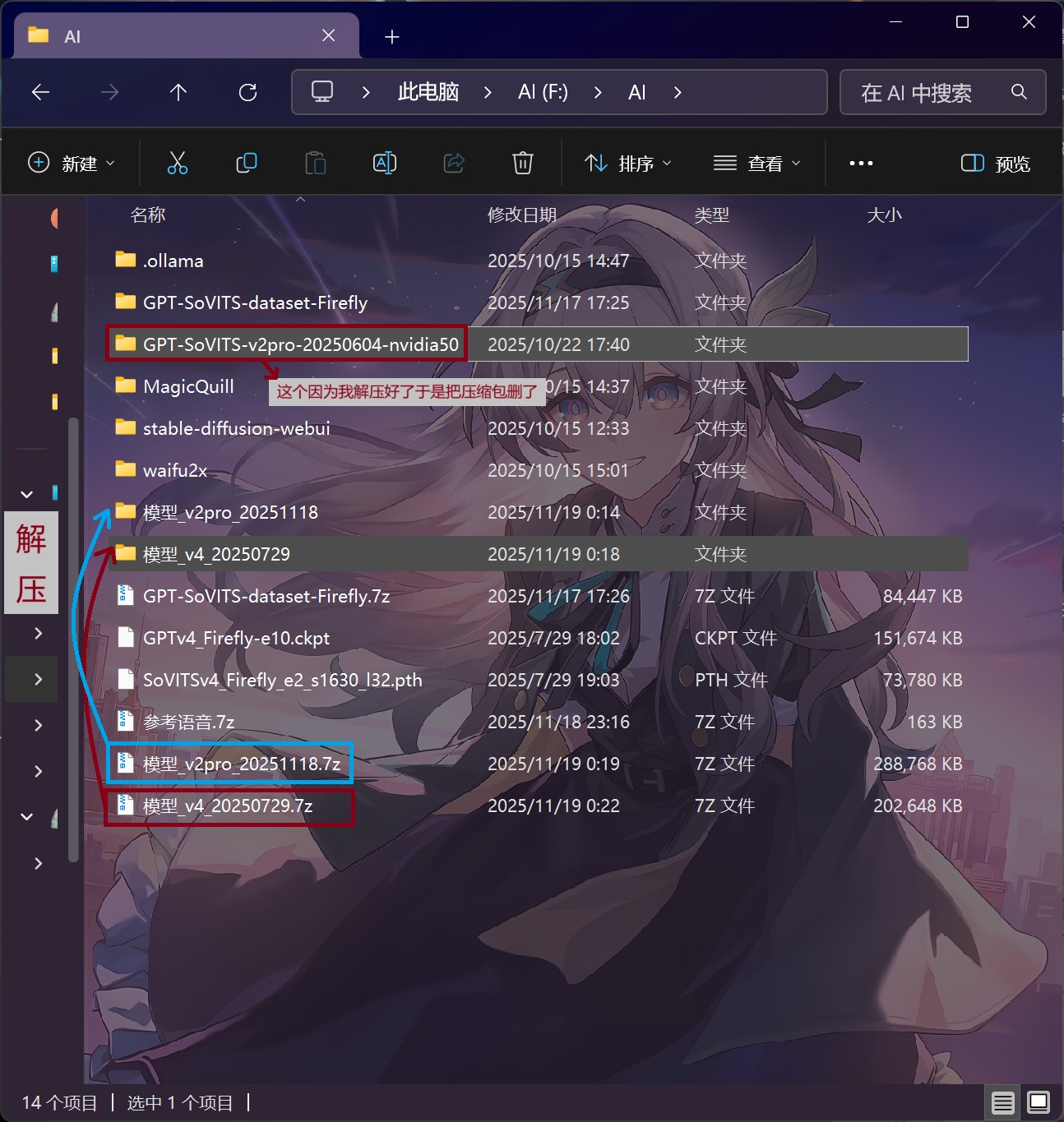
1.2 移动模型 #
将模型移动到正确位置,简而言之,直接将这两个文件夹复制到整合包目录即可
[整合包目录] 指的是你解压的目录,比如:
GPT-SoVITS-v2pro-20250604-nvidia50
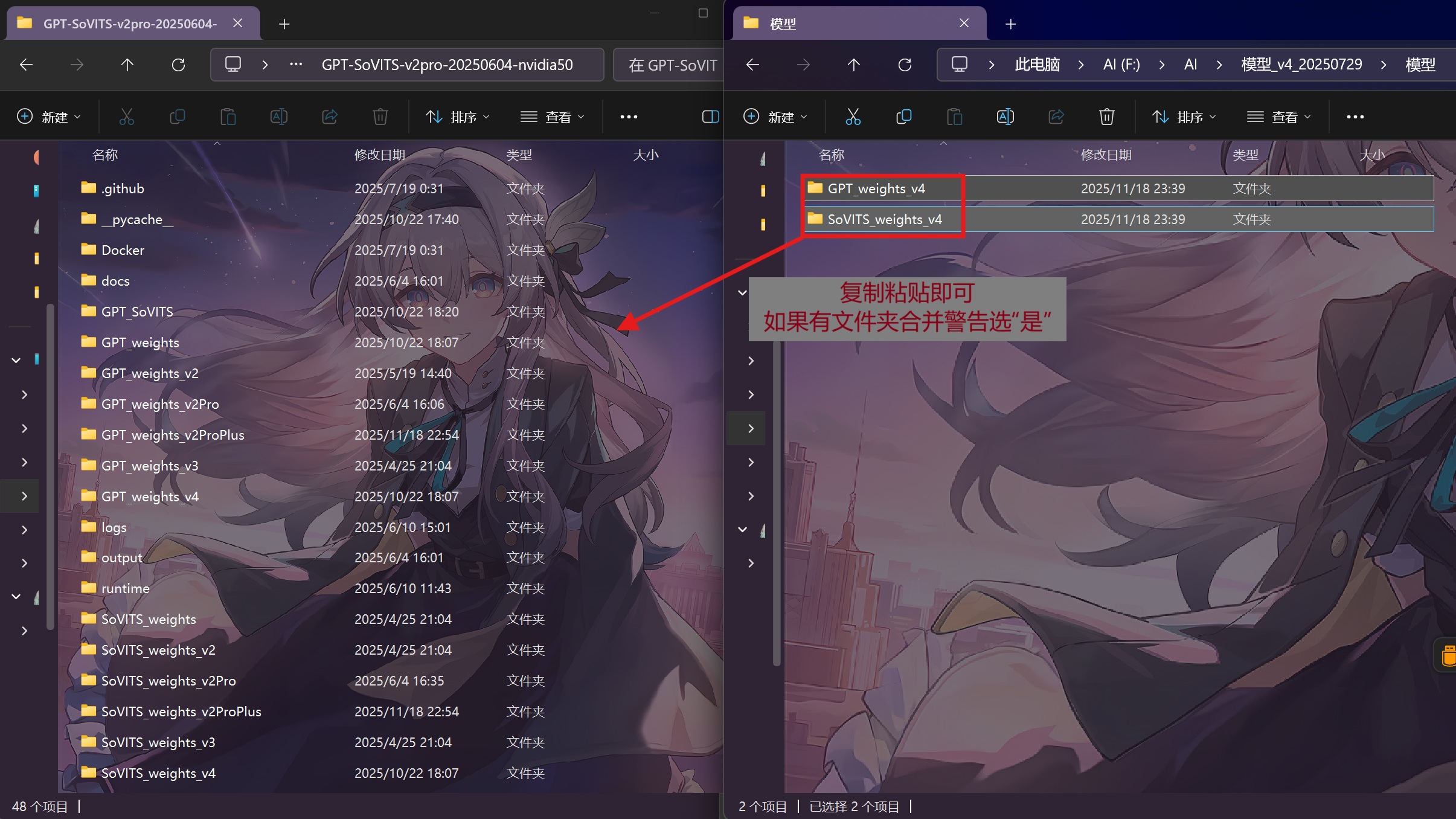
1.3 运行网页端 #
进入刚才解压的目录(我是 GPT-SoVITS-v2pro-20250604-nvidia50)。
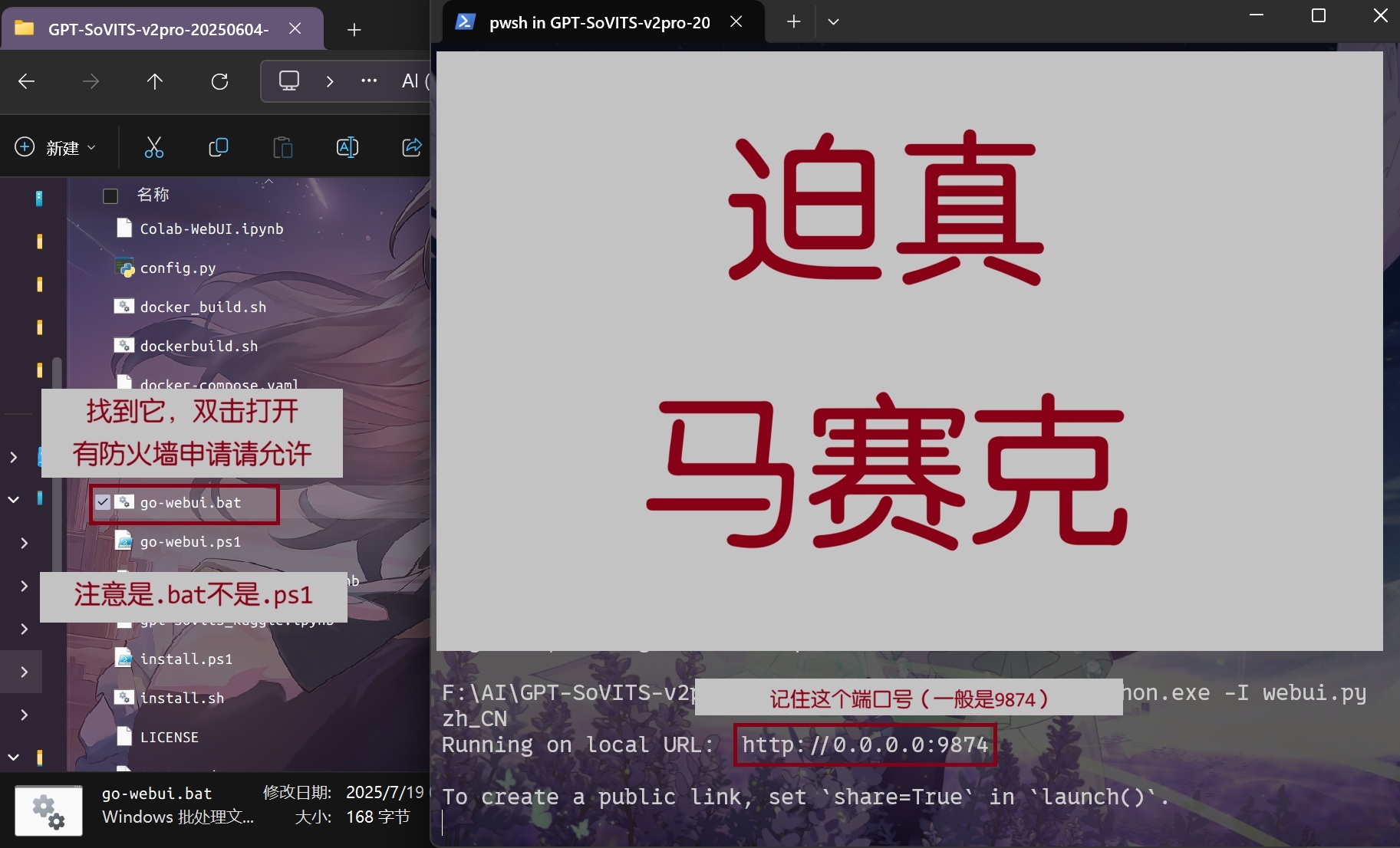
双击运行 go-webui.bat,这时将会从自带的环境中运行 webui。一般会直接弹出浏览器窗口。如果没有,请看下一步。
如果没有打开浏览器 #
你可以在控制台输出的结尾找到类似的字样:
Running on local URL: http://0.0.0.0:9874
记住 9874 这个端口号,然后在浏览器中开:
http://localhost:9874
如果是因为报错没有打开浏览器,请检查端口占用情况(比如是不是已经打开了一个),或者复制报错信息搜索/询问 AI。
1.4 开始推理 #
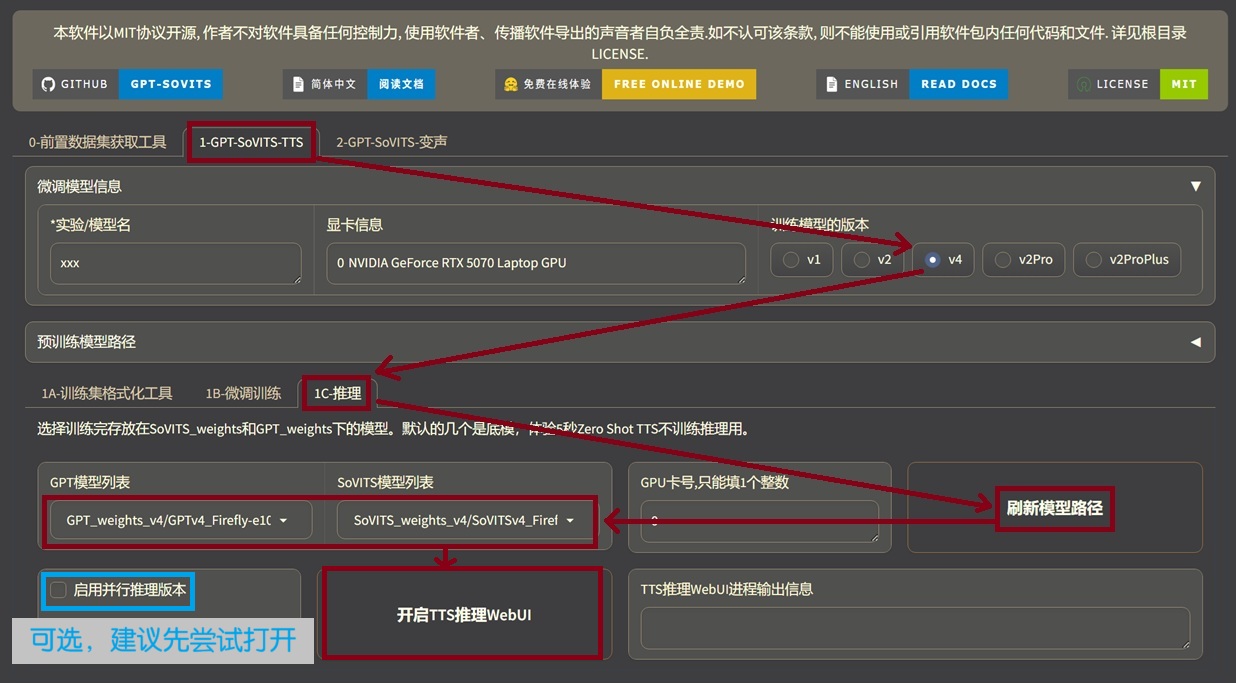
等待一段时间(不要心急,终端静止是正常的,没报错即可),会自动打开 localhost:9872。如果过长时间没有打开,或者看到终端报错(Error ...),请参照 前面的方法 解决。如果是因为配置不足,请考虑租用服务器/云游戏。
然后按照 参考语音.7z 的内容填好参数,点击合成即可
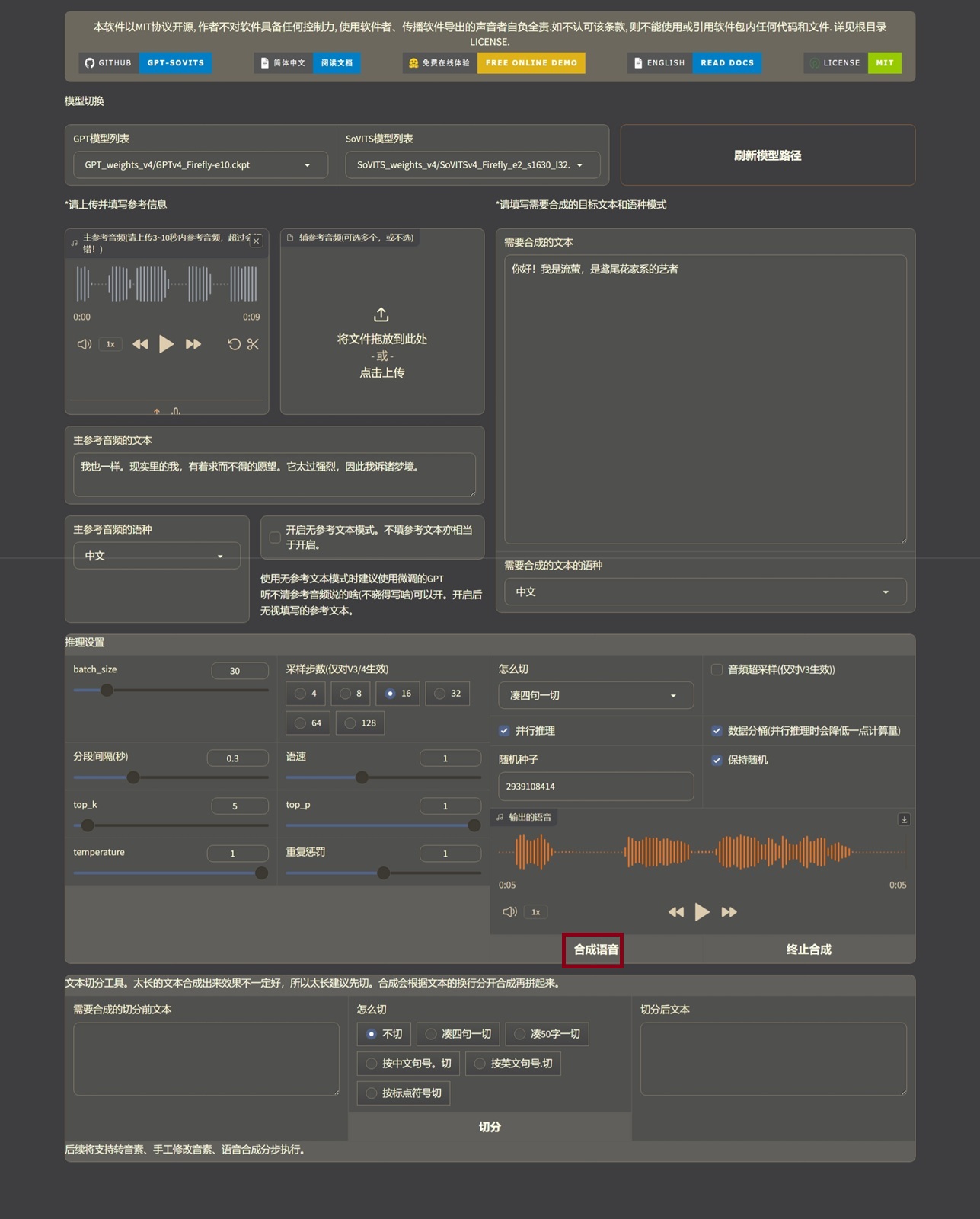
当然,参考语音的语气比较平淡,所以需要其他语气的,请下载完整的训练语音:lovefirefly-archive/语音合成/训练数据(不是说拿来训练,是填入参考文本)
由于 v4 是我本地训练的,现存不足,微调时切分比较细碎,所以模型不那么会停顿,有可能需要后期处理。我特地标注了流萤句首的气息词,用“呃”/“啊”/“呵”+“……”/“、”标注。基本 达到预期效果。
如果需要更好的长句能力、句首换气和高质量停顿,请使用 v2pro。v2pro 也做了语气词优化,不过由于已经是含有完整上下文的长句了,所以主要依靠模型推断,我手动插入语气词的部分其实不多。
2. 如果需要自行微调…… #
参阅 整合包教程
3. 导入 Google Colab #
提示:Colab 在中国大陆访问受限,请自行寻找解决方案
或者参阅 其它平台 的部署。
感谢 tux_la 的整合包。也是 ta 将我的预训练模型打包到 Huggingface 上
3.0 准备 ngrok #
接下来会用到 ngrok,需要注册账号并拿到 Authtoken。如果需要,可以参阅:Nemo尼莫 的 这篇教程(只需要做到注册完毕即可),这里不再赘述。
访问 Your Authtoken - ngrok 并复制 Authtoken 待用。
3.1 下载整合包 #
在 这里 下载 tux_la 制作的整合包。不需要下载微调模型,因为整合包会自动工作。并解压.
压缩包内容:
流萤-tux_la-流螢tts整合包/
├── 導入colab.ipynb
├── 教程.mp4
└── 使用
├── firefly.exe
├── firefly.py
├── link.txt
└── test.wav
3.2 登录 Colab #
自行注册可以正常使用的谷歌账号。然后访问 Google Colab,并登录你的账号。
3.3 使用整合包 #
点击“上传”,然后导入文件,具体而言,是 導入colab.ipynb。
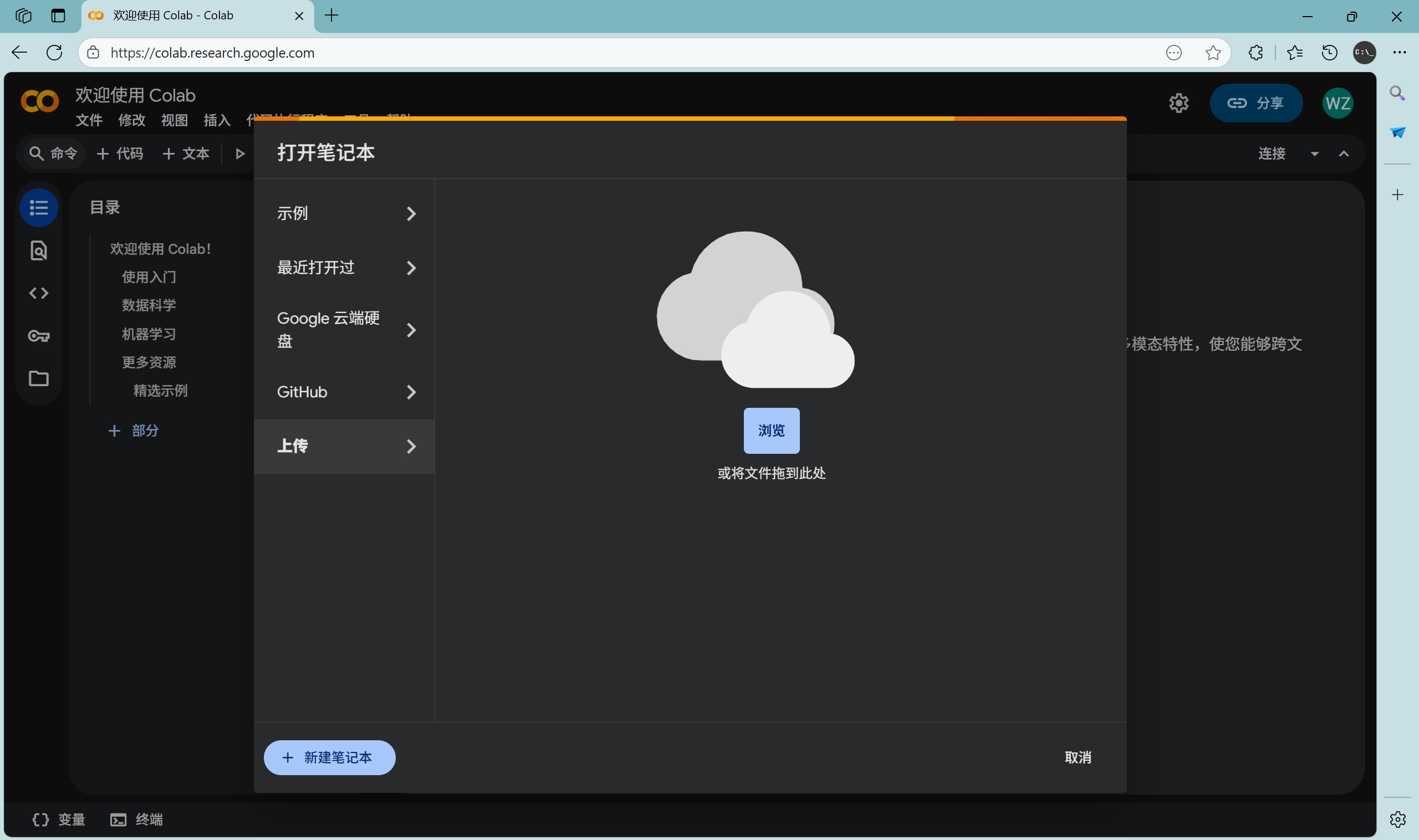
然后依次执行全部命令就好啦!
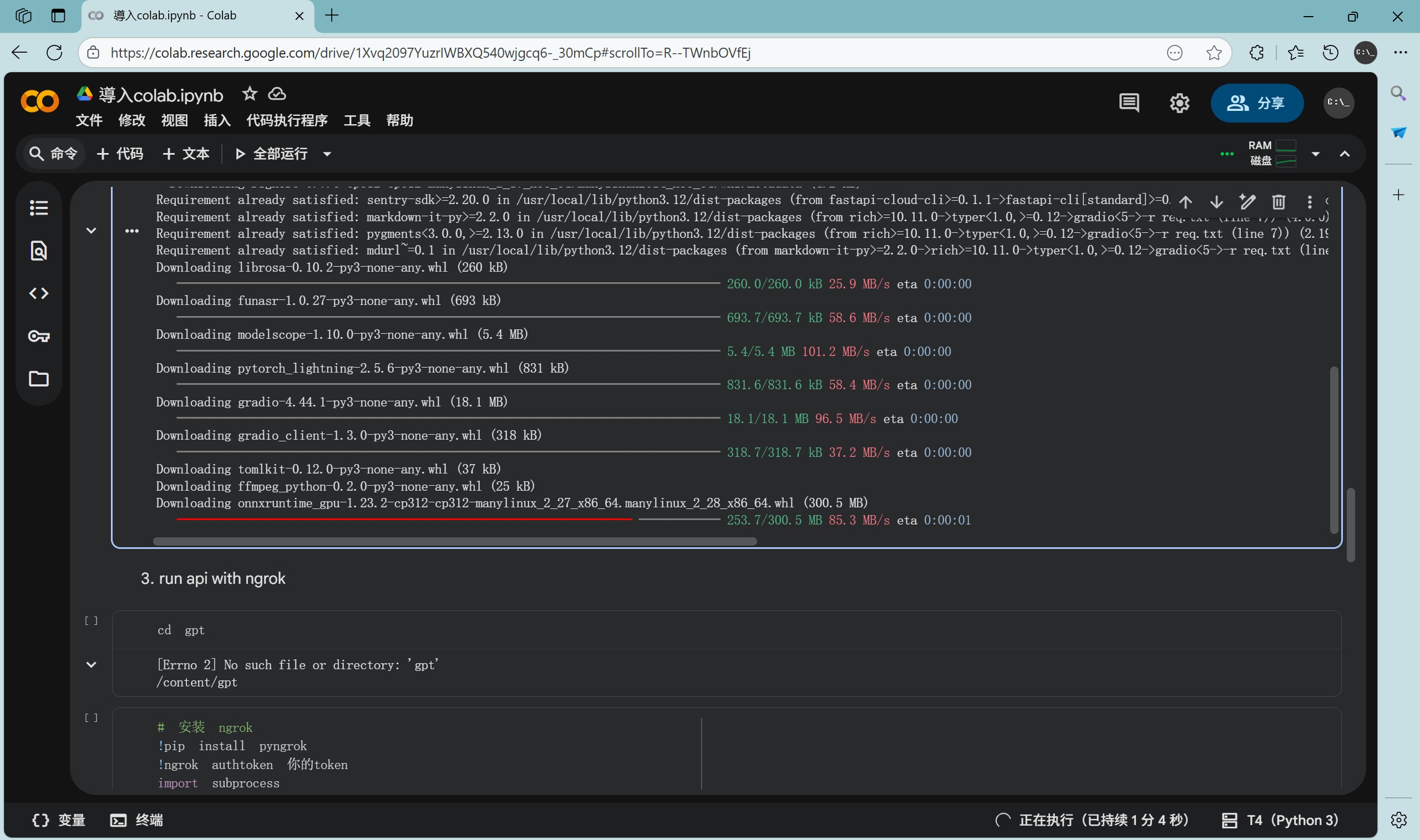
在 pip install -r req.txt 的时候有可能断开连接并显示“执行失败”,这大概是构建依赖时间太长的原因,请耐心等待直到所有包都 Successfully installed。断开连接时在右上角可以尝试手动连接。
最后可能提示
WARNING: The following packages were previously imported in this runtime:
[numpy]
You must restart the runtime in order to use newly installed versions.
不要重启!!不要重启!!!

注意,需要在这部分手动填写你 此前 拿到的的 Authtoken:
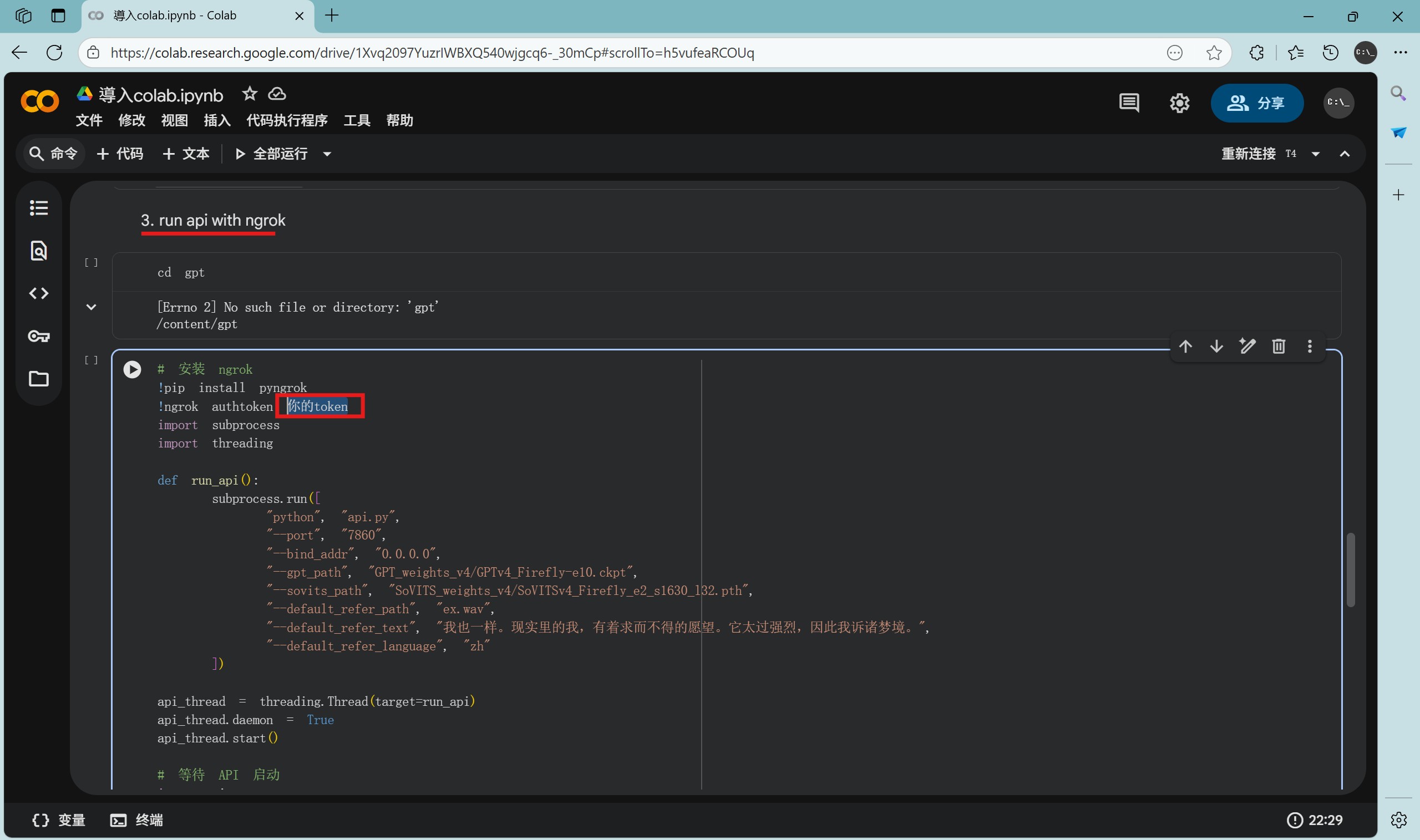
执行完毕后把生成的链接复制下来,替换掉 link.txt 中所有内容,保存。
由于是死循环,所以 Colab 会显示掉线,但是没关系,可以正常终止脚本。
不需要也没办法继续执行 !python api.py,不用管它。
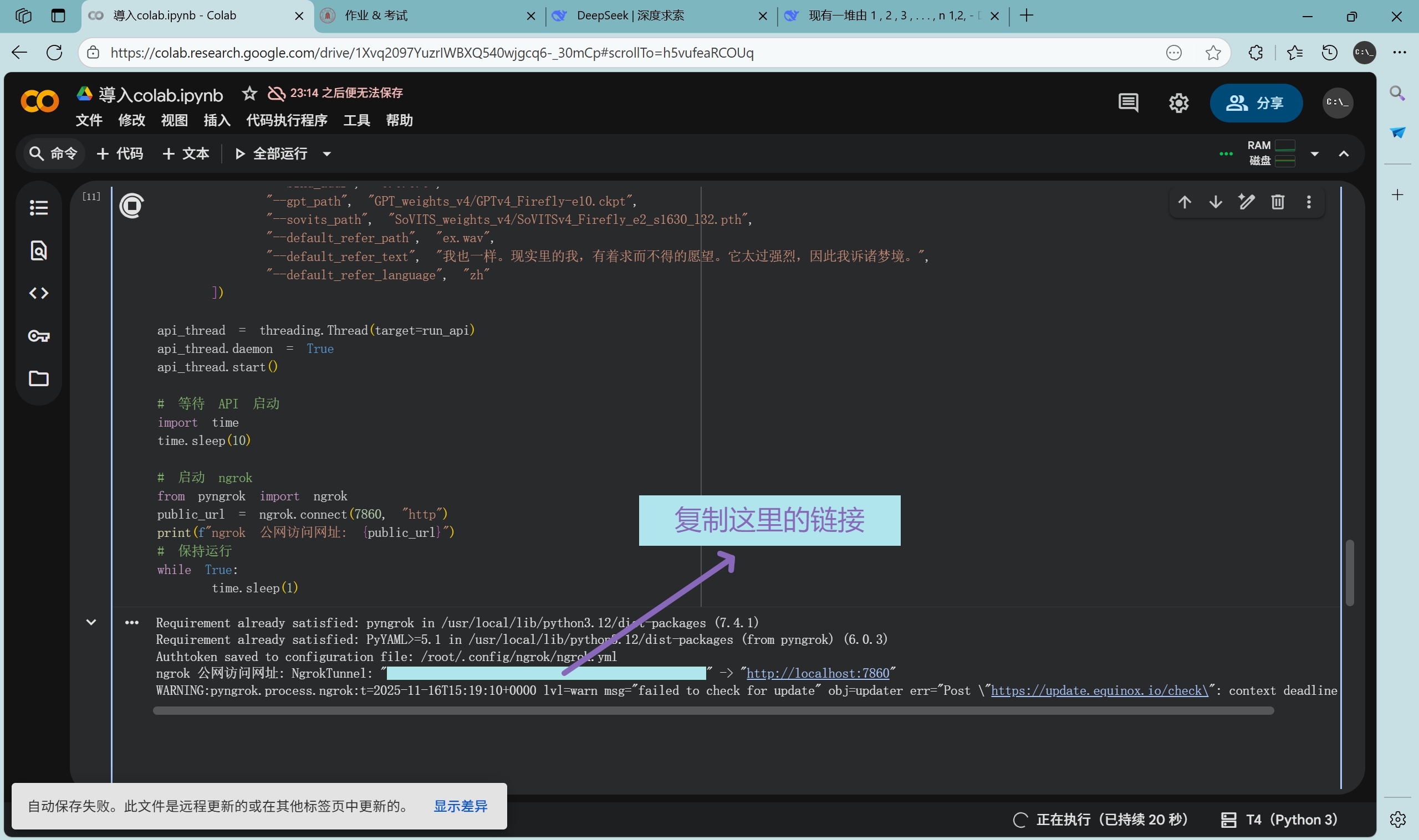
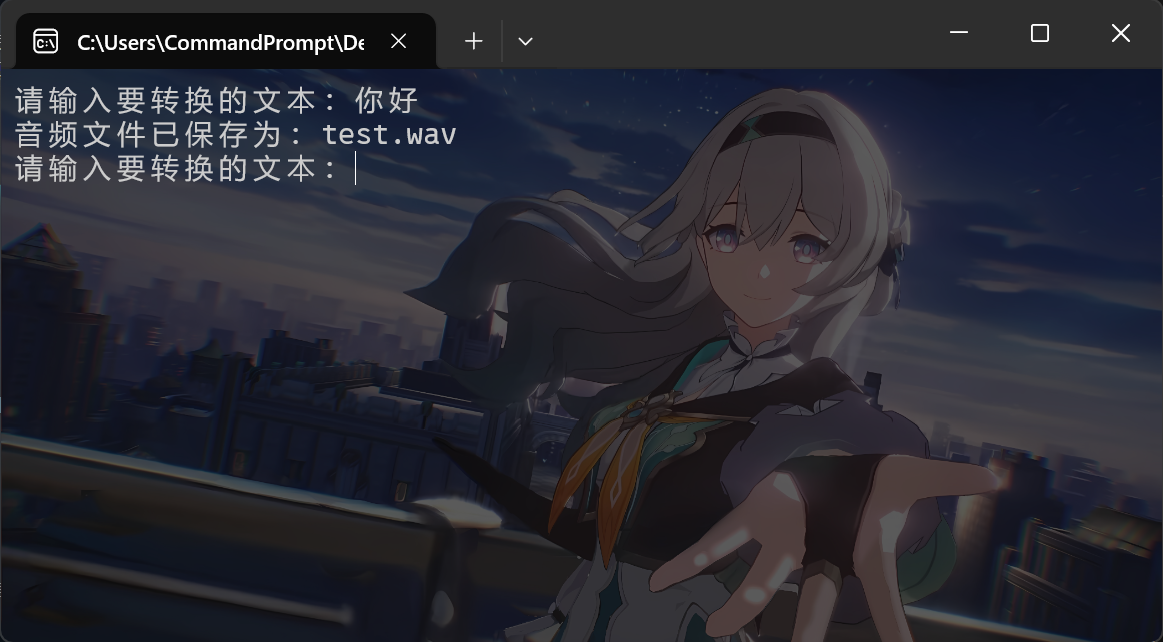
如果需要类似前面的听书效果,请参阅软件的具体 API 要求,并自行修改内网穿透的端口
3.2147483647 教程视频(by: tux_la) #
4. 其他平台部署 #
其实差别不大,为了连接的稳定性,将 導入colab.ipynb 的第一个单元格改为:
!mkdir content
!source /etc/network_turbo && env | grep proxy
!wget -O gpt.zip "https://hf-mirror.com/tuxjhtd/firefly_Gpt-sovit/resolve/7bf2f616f41bf4f0e757f12216949d424aea2d1c/gpt.zip?download=true" --progress=bar:force
!mv gpt.zip ./content
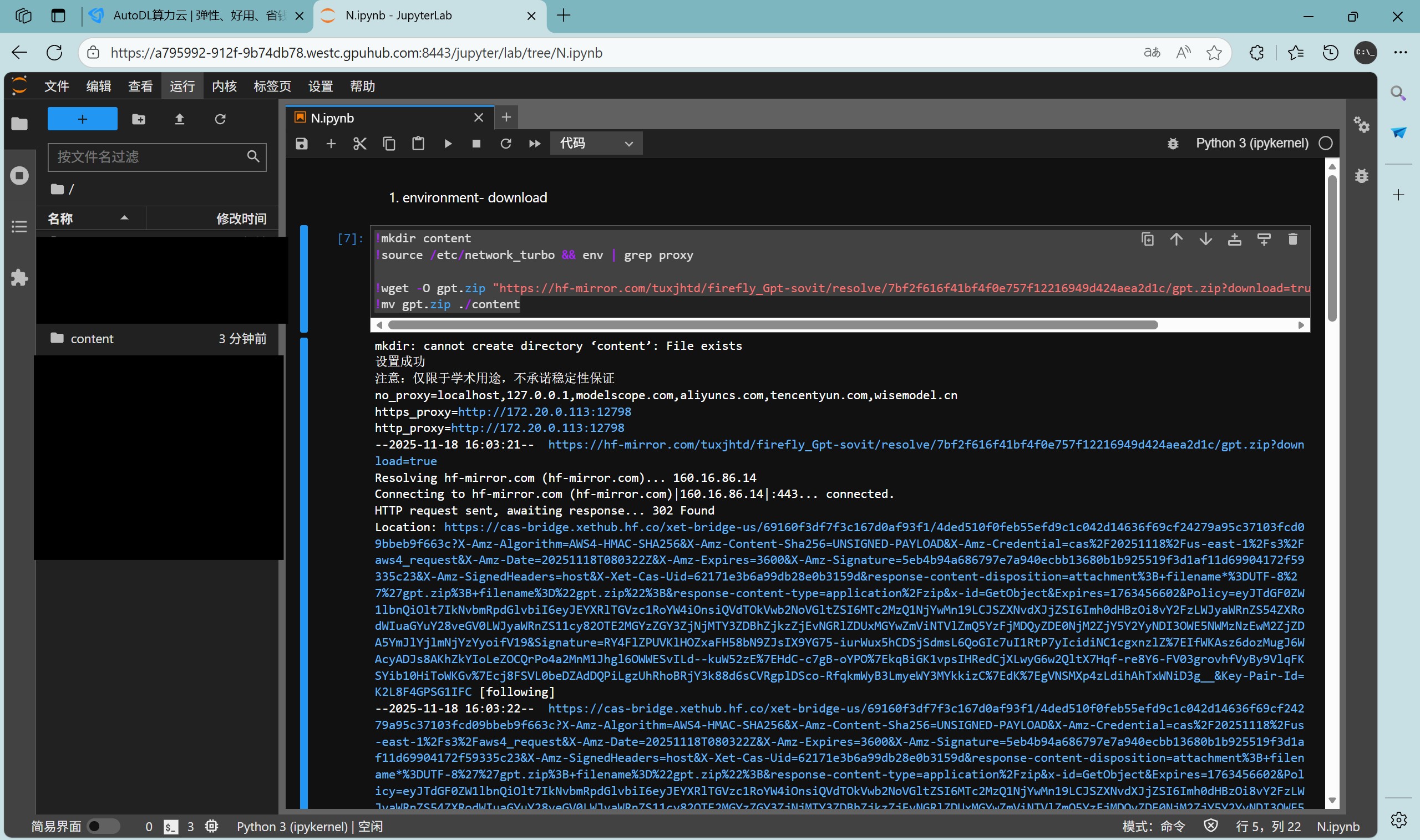
后续 应该 都是差不多的,不过囿于没用高速 G 口,10MB的下载速度实在是感人我便没有继续尝试。
疑似 AutoDL 有自己的端口映射工具,可能 可以代替后面的 ngrok 内网穿透。大概是这个 SSH隧道工具,找好端口穿透即可。
这个解法或许是为数不多的全国内服务一条龙了,但是要给点小钱,取决于租的服务器。
5. Genie-TTS #
直接使用整合包,内含 GUI 图形界面。
- 注意:
pip install genie-tts的安装版本已经完全滞后(v1.x),其中编码的链接已经迁移。需要克隆仓库并使用pip install .安装当前版本(v2.0.2)才能正常使用。
服务端和 Python API 的使用方法也参照上面的文档。
关于 Android 整合包,请转到我的 仓库 查阅,下载请访问 Release 页面。
整合包分为 3 个版本,分别是:
genie_tts_portable-full-[version]: 完整版本,包括 Genie-TTS 本体以及额外的 Torch(模型转换需要)和预装模型。genie_tts_portable-noTorch-[version]: 精简版本,不包含 Torch,如果不需要进行模型转换,可以节省空间。genie_tts_portable-noTorch_noModel-[version]: 极简版本,不包含 Torch 和预装模型。
提供 2 种打包格式,分别是 .zip 和 .7z。7z 格式可以减少 30%~50% 的传输体积,但解压速度较慢(或者说非常慢)。zip 格式未经压缩,传输体积较大,但解压速度非常快。根据需要选择下载。
解压后进入目录,运行:
chmod +x install
sh install
根据提示操作即可。具体参阅随附的 README_zh.md 或 README_en.md。
什么都没有喵。